Running LLM’s Locally
Large Language Models (LLMs) are powerful AI models designed to understand and generate human-like text based on vast amounts of data. They are capable of performing a variety of tasks, such as answering questions, summarizing information, translating languages, and even generating code. These models, often built using transformer architectures, learn from enormous datasets to predict the next word in a sequence, which gives them a strong ability to generate coherent and contextually relevant responses. LLMs have applications across industries, including customer service, research, content creation, and automation.
Benefits of Running LLM’s On Your Computer
Running a Large Language Model (LLM) locally on your machine offers key benefits for both individuals and businesses:
- Privacy and Security: Sensitive data stays on your own machine, reducing the risk of data breaches or leaks when using third-party cloud services.
- Cost Savings: Avoid ongoing fees associated with cloud-based AI services by utilizing your own hardware for processing.
- Customization: Tailor the LLM to your specific needs, fine-tuning the model for more relevant and effective results.
- Low Latency: Get faster, real-time responses without relying on external servers, improving efficiency in real-time applications.
- Offline Access: Use the LLM without needing an internet connection, which is useful in restricted or remote environments.
In Comes Qwen2.5 LLM
Qwen 2.5 is an advanced LLM, known for its ability to perform more sophisticated tasks with improved efficiency and accuracy. It has been fine-tuned to understand and generate text with greater clarity, leveraging an architecture that allows it to handle diverse and complex inputs better. This model represents a significant leap in language processing and AI applications, making it a powerful tool for developers and businesses alike.
How To Get Started Running Qwen2.5 1.5B
To run Qwen2.5 LLM on your local machine, you can follow these steps using Hugging Face’s transformers library.
1. Install Python
Mac
Most modern versions of MacOS come pre-installed with Python 2, however Python 3 is now the standard and should be installed as well. Python 3 can be installed using the official Python 3 installer.
- Go to the Python Releases for Mac OS X page and download the latest stable release macOS 64-bit/32-bit installer.
- After the download is complete, run the installer and click through the setup steps leaving all the pre-selected installation defaults.
- Once complete, we can check that Python was installed correctly by opening a Terminal and entering the command
python3 --version. The latest Python 3.7 version number should print to the Terminal.Advanced
Since our system now has both Python 2 (which came pre-installed) and Python 3, we must remember to use the
python3command (instead of justpython) when running scripts. If you would rather not have to remember thepython3command and just usepythoninstead, then creating a command alias is your best bet.
- Execute
open ~/.bash_profilefrom a Terminal (if the file was not found, then runtouch ~/.bash_profilefirst). - Copy and paste
alias python="python3"into the now open.bash_profilefile and save. - While we’re at it, go ahead and copy and paste
alias pip="pip3"into the file as well in order to create an alias for the Python 3pippackage manager. - Finally, restart the Terminal and run
python --version. We should see the exact same output as runningpython3 --version.
Windows
Follow the below steps to install Python 3 on Windows.
- Go to the Python Releases for Windows page and download the latest stable release Windows x86-64 executable installer.
- After the download is complete, run the installer.
- On the first page of the installer, be sure to select the “Add Python to PATH” option and click through the remaining setup steps leaving all the pre-select installation defaults.
- Once complete, we can check that Python was installed correctly by opening a Command Prompt (CMD or PowerShell) and entering the command
python --version. The latest Python 3.7 version number should print to the console.
2. Install Required Libraries
First, ensure you have the necessary dependencies installed. You’ll need transformers and torch. You can install them using pip:
pip install transformers torch
3. Set Up the Model and Tokenizer and Run It
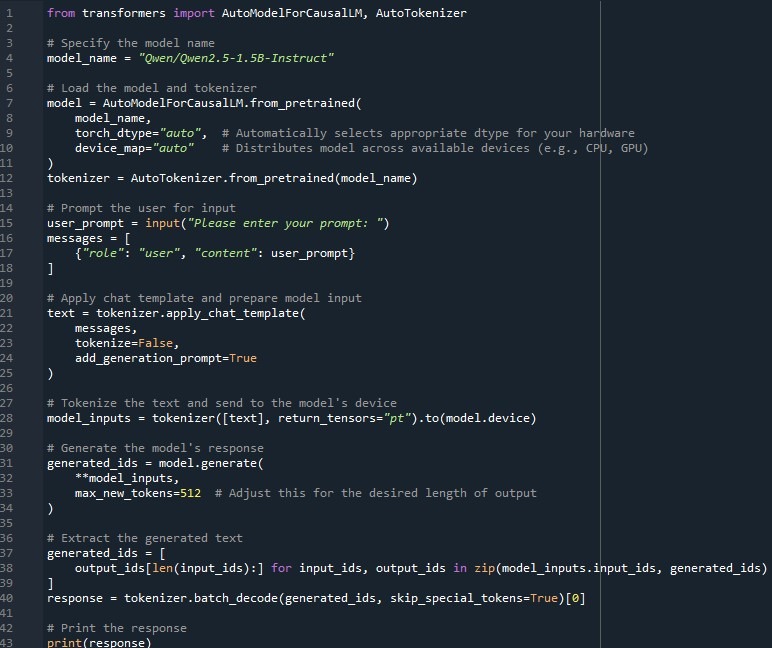
The Qwen2.5 1.5B Instruct LLM can be loaded using Hugging Face’s AutoModelForCausalLM and AutoTokenizer classes. In this example, the model is loaded with automatic configuration for your machine’s hardware, including GPU if available.
from transformers import AutoModelForCausalLM, AutoTokenizer
# Specify the model name
model_name = “Qwen/Qwen2.5-1.5B-Instruct”
# Load the model and tokenizer
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=”auto”, # Automatically selects appropriate dtype for your hardware device_map=”auto” # Distributes model across available devices (e.g., CPU, GPU)
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Prompt the user for input
user_prompt = input(“Please enter your prompt: “)
messages = [{“role”: “user”, “content”: user_prompt}]
# Apply chat template and prepare model input
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Tokenize the text and send to the model’s device
model_inputs = tokenizer([text], return_tensors=”pt”).to(model.device)
# Generate the model’s response
generated_ids = model.generate(**model_inputs, max_new_tokens=512 # Adjust this for the desired length of output)
# Extract the generated text
generated_ids = [output_ids[len(input_ids)] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Print the response
print(response)